- Export et import simultané des données extraites (TCDETS)
- Critères de soumission du traitement TCDETS
- Compte rendu du traitement, fichiers de trace générés
- Fonctionnement et suivi de l'export, résultat attendu
- Identifiant de l'export, répertoires de l'export
- Les données extraites
- Le fichier guide de l'import des données
- Fonctionnement et suivi de l'import, résultat attendu
- Identifiant de l'import, répertoire de l'import
- Les données importées
- Les données qui n'ont pas pu être importées
- Paramétrage
- Connexion à la base de données
- Comportement en cas d'existence de données pour l'établissement cible (Paramètre QREPRM, occurrences EM et EM.nomTable)
- Inhibition systématique de la duplication d'une application (Paramètre QREPRM, occurrence QRE_$yyy)
- Inhibition systématique de la duplication d'une table (Paramètre QREPRM, occurrence SK.nomTable)
- Contraintes additionnelles : définition d'un contexte (Paramètre QRECXyyy)
- Application des autorisations/interdictions de la transaction GTMME (Paramètre QREPRM, occurrence USEGTMME)
- Réduire le volume de fichiers de compte-rendu générés
- Import des données en ignorant leur état
Module Référentiels : duplication d'établissements
La vocation de ce module est le transfert de données cohérentes entre établissements. Cela signifie que, pour chaque entité à transférer, les données connexes indispensables à l'utilisation de celle-ci dans le cadre du produit Cegid XRP Ultimate sont également prises en compte : le transfert d'un tiers, par exemple, entraînera également celui de ses adresses, de ses domiciliations, des paramètres associés, etc.
Une des applications de ce module est : Module Référentiels : Duplication d'établissements : il s'agit dans ce cas de transférer les référentiels associés à un établissement et de les réinsérer dans la même base de données en changeant l'établissement associé.
La duplication exporte en masse le contenu des tables d'un établissement dit "modèle" et l'importe sur un ou plusieurs établissement(s) dit(s) "cible(s)"en effectuant les contrôles d'intégrité.
Permet la création d'un nouvel établissement (phase d'initialisation) par copie d'un établissement modèle.
L'objectif principal étant la maintenance d'un référentiel.
Le traitement TCDETS permet de sélectionner les données des tables à exporter et exécute simultanément l'import de celles-ci sur un ou plusieurs établissement(s).
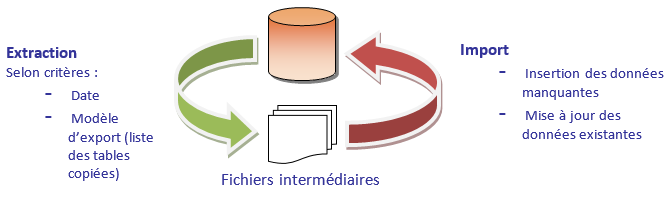
Création ou mise à jour des données sur l'établissement sur lequel se fait l'import des données.
Quelques restrictions :
- la duplication s'effectue sur la même base de données ;
- traitement des tables dites de structure et de paramétrage ;
- sauf quelques exceptions, les tables dites d'exploitation sont ignorées ;
- les tables ne faisant pas référence à l'établissement sont ignorées car même base de données ;
- l'établissement sur lequel on importe les données doit exister sur la base cible, il n'est pas créé par ce module. De plus, le tiers correspondant à l'établissement doit être défini dans les associations tiers-établissement (GATE de nature = E).
- un établissement donné ne devrait être alimenté que depuis un établissement modèle et un seul. En effet, si un établissement E est alimenté successivement par l'établissement A puis l'établissement B, des incohérences risquent d'apparaître durant la seconde duplication et des rejets seront produits.
A l'import des données, les contrôles d'intégrité sont faits en appelant les procédures stockées d'insertion et/ou de mise à jour.
Export et import simultané des données extraites (TCDETS)
Le traitement TCDETS facilite la duplication, il évite l'exécution d'un traitement pour chaque phase de la duplication.
En effet celui-ci permet la sélection des données à exporter sur un établissement modèle et duplique les données sélectionnées sur un ou plusieurs établissement(s).
Attention :
- Pas de vérification possible des données exportées avant la copie sur les établissements cibles.
- Si la duplication s'effectue sur un nombre important d'établissements, les temps d'exécution peuvent être relativement longs.
- On ne peut pas lancer deux traitements de duplication simultanément.
AVANT LE LANCEMENT D'UN IMPORT IL EST IMPERATIF D'AVOIR UNE SAUVEGARDE DE LA BASE DE DONNEES SUR LAQUELLE L'IMPORT S'EFFECTUE
Critères de soumission du traitement TCDETS
Données créées, modifiées depuis le
Sélection des données dont leur date de création ou de modification est supérieure ou égale à cette date.
Dans le cadre de la maintenance d'un référentiel, il est conseillé de procéder à la duplication d'établissement une première fois en précisant une date lointaine pour sélectionner un maximum de données (phase d'initialisation), puis de maintenir régulièrement les données en activant le paramétrage dans GTMME.
GTMME
Exceptionnellement, ce critère permet de demander à ce que la duplication suive les contraintes codées pour la maintenance des référentiels (transaction GTMME).
Si le critère vaut :
- "N" : les contraintes de la transaction GTMME sont ignorées (valeur par défaut).
- "P" : le traitement recherche dans le paramétrage de la transaction GTMME les données relatives à l'établissement modèle dont le paramètre standard "Rôle" vaut "O". Il en déduit les établissements cibles à alimenter.
Etablissement modèle : si l'établissement modèle n'est pas renseigné (valeur "." dans le critère de soumission), on recherche dans la transaction GTMME la liste des établissements modèles à utiliser. Pour qu'un établissement soit ajouté à cette liste, il faut que le paramètre standard "Rôle" de GTMME soit à "O". Pour chaque établissement trouvé, le traitement effectue un export, puis un import vers les établissements cibles correspondants.
Etablissements cibles : on ignore les saisies éventuellement réalisées dans les critères de soumission "Fourchette d'établissements cibles" et "Chemin de composition". La liste des établissements cibles pour l'établissement modèle traité est lue dans le paramétrage GTMME. Pour qu'un établissement soit ajouté à cette liste, il faut que le paramètre standard "Rôle" de GTMME soit à "O".
- "p" : même comportement que "P", à ceci près que l'on ne tient plus compte de la valeur du paramètre standard "Rôle" de GTMME.
- "C" : non seulement les établissements cibles sont déduits de la transaction GTMME, mais en plus, les autorisations/interdictions décrites dans ce paramétrage sont prises en compte. Si par exemple, dans la transaction GTMME, la table OECPT est signalée comme ne devant pas être mise à jour, une contrainte contextuelle sera automatiquement ajoutée, qui interdira toute modification autre que technique sur cette table au moment de l'initialisation.
- "E" : seules les tables spécifiées dans la transaction GTMME sont dupliquées. Pour ces tables, le paramètre standard "Rôle" doit être égal à "O" dans GTMME.
Attention aux rejets, lors de l'import sur le ou les établissements cibles, si des entités dont ces tables ont besoin sont de ce fait ignorées.
A noter que les tables exportées sont toujours celles données par le modèle de l'export demandé.
Contexte
Ce critère permet de demander la prise en compte de contraintes additionnelles, que l'on peut définir sous forme d'occurrences de paramètres dans GPAR.
Il s'agit de demander à ce qu'une table ne soit pas traitée par l'export, ou de demander au moment de l'import à ce qu'une table ne fasse pas l'objet d'insertions ou de mises à jour.
Pour plus de détail sur la définition d'un contexte, voir "Module Référentiels : Duplication d'établissements (Initialisation)".
Modèle de l'export
Il s'agit du code du regroupement donnant la liste des tables à exporter.
La liste des regroupements disponibles est décrite dans le document "Module Référentiels : Duplication d'établissements (Initialisation)".
Etablissement modèle
Sélection des données référencées sur cet établissement.
Etablissement(s) cible(s)
Les données exportées sont insérées et/ou mises à jour sur un ou plusieurs établissement(s).
Pour dupliquer sur un seul établissement : saisir cet établissement dans les bornes de début et de fin de la fourchette, ne pas préciser de chemin de composition.
Pour dupliquer sur plusieurs établissements :
- Soit saisir une fourchette d'établissements dans les bornes de début et de fin, ne pas préciser de chemin de composition.
- Soit saisir le chemin de composition, la fourchette sur les établissements doit sélectionner un seul établissement. Les données sont alors sélectionnées pour tous les établissements appartenant à la hiérarchie d'établissements dont le père est l'établissement choisi.
Compte rendu du traitement, fichiers de trace générés
Classiquement, il est possible de suivre dans la consultation des travaux (CJOBU) le déroulement de l'export, puis de l'import des données.
Lorsque l'état du job passe à T, cela signifie qu'il s'est achevé sans erreur technique. Il peut cependant y avoir des erreurs fonctionnelles (cf. statut du job).
Attention : un travail à l'état T ne signifie pas que toutes les données ont correctement été importées.
Le traitement de duplication génère de nombreux fichiers de trace (logs, errors, etc.) stockés dans un répertoire dédié, appelé "identifiant de l'export".
Ce répertoire dédié est un sous-répertoire du répertoire "qenvironnements" se situant dans le répertoire des spools.
Une fois le traitement terminé, le répertoire "identifiant de l'export", contenant les logs de TCDETS, est compressé (gain de volume).
L'archive de ces logs est ensuite accessible et téléchargeable depuis CJOBU via la transaction associée GTCFIJ.
Comme les fichiers générés sont dans GTCFIJ, ils sont épurés régulièrement par le processus standard d'épuration des jobs.
Fonctionnement et suivi de l'export, résultat attendu
Le traitement extrait les données des tables référencées dans le "modèle de l'export" sélectionné sur l'établissement demandé et génère autant de fichiers contenant les données que de tables traitées.
L'export parcourt successivement tous les noeuds de l'arbre constitué par application du modèle d'export fourni à la soumission de TCDETS. Chaque table donne lieu à la création d'une table temporaire, qui s'enrichit au fil de ce travail des données correspondant aux critères de soumission. Au passage, il applique les règles éventuellement consignées sous la forme de "modificateurs" (filtres, verrous, etc.). Lorsque l'arbre est entièrement parcouru, le contenu des tables temporaires est extrait sous forme de fichiers dans un répertoire dédié. Les tables de travail sont alors supprimées.
L'export produit un fichier par table à dupliquer, contenant les données sélectionnées au regard des critères de soumission fournis. Ces fichiers sont au format texte et peuvent, sous réserve d'une volumétrie limitée, être directement consultés sous Excel.
Il produit également un fichier guide de l'import, contenant l'ensemble des instructions à suivre pour importer de façon cohérente les données extraites.
Identifiant de l'export, répertoires de l'export
Le format de l'identifiant de l'export, {IDe} sur 19 caractères, est composé comme ceci :
QRE_MMJJ.HHMMSSxXXX
QRE : code fixe du Module Référentiels
MMJJ : mois, jour de lancement de l'export
HHMMSS : heure, minutes, secondes de lancement de l'export
xXXXX : un code aléatoire
Exemple : QRE_1024.143352xN41
En tant que sous-répertoire de ce dernier, on trouvera :
- le répertoire "logs" ;
- un répertoire par import réalisé à partir de cet export.
Le répertoire d'export contient également les fichiers des données exportées (exemple : QRE_1024.143352xN41_amacp.xls) ainsi que le fichier guide de l'import (exemple : QRE_1024.143352xN41_dataguide.xml).
Les principaux fichiers de trace du répertoire "logs" sont :
- {IDe}.err Erreurs techniques éventuelles ;
- {IDe}.log Traces techniques détaillées ;
- {IDe}.wrn Avertissements éventuels ;
- {IDe}_traceParam.properties Critères de soumission ;
- {IDe}_traceModifiers.txt Liste des modificateurs utilisés ;
- {IDe}_traceRequest.csv Liste des requêtes jouées et leur résultat.
Un modificateur est une instruction prenant effet dans le cadre d'un contexte bien particulier de la hiérarchie. Cela peut être un filtre, une inhibition (verrou), une substitution, une action.
Le fichier des traces présente la liste de tous les modificateurs rencontrés, avec pour chacun d'eux : le sens (Export ou Import), le type (Filtre, Verrou, Substitution, Action), la source (c'est-à-dire le composant de la hiérarchie dont la présence apporte le modificateur), la cible (c'est-à-dire l'endroit de la hiérarchie où s'applique le modificateur), le nom, le modificateur équivalent s'il existe.
Les données extraites
Il y a dans le répertoire "identifiant de l'export" UN fichier de données par table concernée par l'export dont le nom est : {IDe}_{table}.xls
Le format retenu est de type CSV :
- les diverses occurrences sont séparées les unes des autres par un saut de lignes ;
- les champs d'une même occurrence sont séparés les uns des autres par le caractère tabulation (code ASCII 9).
Le fichier porte l'extension .xls de sorte à permettre son ouverture directe sous Excel® (Attention, si le fichier est très volumineux, mieux vaut éviter cette manipulation !).
La première ligne de chaque fichier contient le nom de la table.
La seconde ligne de chaque fichier contient la description du séparateur utilisé sous la forme :
Sep : asc(codeAscii) avec codeAscii = code ASCII du séparateur
La troisième ligne de chaque fichier contient la description des colonnes.
La quatrième ligne contient la description des types de données pour les colonnes en question.
Les autres lignes contiennent les données.
La première colonne contient le numéro de l'occurrence.
La deuxième colonne contient le numéro de la requête ayant extrait la donnée.
Les autres colonnes décrivent les colonnes de la table.
Les colonnes NULLES ont pour valeur le caractère de code ASCII 0.
Le fichier guide de l'import des données
Ce fichier contient les instructions à suivre pour utiliser les données sélectionnées dans le cadre d'une opération d'import.
Nom : _{IDe} _dataguide.xml
On y trouve :
- La fonctionnalité à mettre en oeuvre (transfert de référentiel, annulation) ;
- La version de l'outil ayant réalisé l'export ;
- Le nombre total d'occurrences à traiter ;
- La liste des tables à traiter, avec, pour chacune d'entre elles, le nombre d'occurrences à traiter, le fichier concerné, et éventuellement les colonnes correspondant à des numéros internes ;
- Les modificateurs à mettre en oeuvre dans le cadre du traitement des données.
Fonctionnement et suivi de l'import, résultat attendu
L'import est lancé dans la foulée de l'export. Il charge le fichier guide des données, qui lui indique dans l'ordre les tables à alimenter. Le traitement charge les données contenues dans les fichiers issus de l'export sur l'établissement demandé et génère dans un répertoire dédié, appelé "identifiant de l'import", autant de fichiers que de tables traitées.
Les fichiers décrits dans le fichier guide des données sélectionnées sont traités successivement. Pour chacun d'eux, une table temporaire est créée dans laquelle toutes les occurrences sont dans un premier temps chargées. Dans un second temps, les occurrences présentes dans la table temporaires et absente de la table cible sont insérées ; les autres donnent lieu à des mises à jour.
Les données sont créées ou mises à jour sur la base cible en effectuant préalablement des "substitutions de valeurs" (par exemple, affectation du nouvel établissement, réinitialisation d'un montant, etc.) et aussi éventuellement des "actions".
Les "actions" sont nécessaires dans des cas plus complexes d'affectation de valeurs (par exemple, affectation sur un champ d'une valeur par défaut suivant des critères).
La création et la mise à jour des données sur la base cible passe par l'appel des procédures stockées pour contrôler l'intégrité des données et garder ainsi la cohérence de la base. En cas d'échec d'une procédure, l'occurrence n'ayant pu être traitée est tracée dans le fichier de rejet correspondant à la table traitée, avec le message d'erreur.
Nécessité d'établir un ordre de traitement des tables à l'import (les tables sans aucune référence à d'autres tables sont importées en premier). Le but étant d'éviter un maximum d'erreur d'existence des données dépendantes lors de l'appel des procédures stockées.
Un fichier exploité lors de l'import donne :
- la liste des tables dans l'ordre d'exécution de l'import ;
- pour chaque table si besoin un "filtre" pour limiter les enregistrements importés ;
- pour chaque table, la procédure à appeler en création et celle en mise à jour ;
- une même table peut être présente plusieurs fois dans le fichier si les occurrences doivent être importées en plusieurs fois si leur traitement dépend de l'import d'autres tables.
Lorsque l'ensemble des instructions d'import a été balayé, l'import les parcours de nouveau si des rejets ont été rencontrés. On autorise jusqu'à 5 passages maximum.
Identifiant de l'import, répertoire de l'import
A l'instar de ce qui se produit pour l'export, un répertoire est créé pour chaque import effectué à partir des données exportées. Ce répertoire a pour nom l'identifiant de l'import concerné, et est généré en tant que sous-répertoire du répertoire de l'export d'origine.
Il contient :
- le répertoire "logs" contenant les traces de l'import ;
- le répertoire "errors" des rejets ;
- les fichiers de données effectivement importées.
L'import génère des fichiers notamment ceux nécessaires à l'annulation de l'import dans le répertoire /qenvironnements/{IDe}/{IDi}.
Avec :
{IDe} : identifiant de l'export
{IDi} : identifiant de l'import sur 19 caractères composé comme ceci :
QRE_MMJJ.HHMMSSxXXX
QRE : code fixe du Module Référentiels
MMJJ : mois, jour de lancement de l'import
HHMMSS : heure, minutes, secondes de lancement de l'import
xXXXX : un code aléatoire
Les principaux fichiers de trace du répertoire "logs" sont :
- {IDi}.err Erreurs techniques éventuelles ;
- {IDi}.log Traces techniques détaillées ;
- {IDi}.wrn Avertissements éventuels ;
- {IDi}_traceParam.properties Critères de soumission ;
- {IDi}_traceModifiers.txt Liste des modificateurs utilisés.
Les données importées
Il y a dans le répertoire "identifiant de l'import" UN fichier de données par table concernée par l'import dont le nom est : {IDi}_{table}.xls
Le format retenu est de type CSV :
- les diverses occurrences sont séparées les unes des autres par un saut de ligne ;
- les champs d'une même occurrence sont séparés les uns des autres par le caractère tabulation (code ASCII 9).
Le fichier porte l'extension .xls de sorte à permettre son ouverture directe sous Excel® (Attention, si le fichier est très volumineux, mieux vaut éviter cette manipulation !).
La première ligne de chaque fichier contient le nom de la table.
La seconde ligne de chaque fichier contient la description du séparateur utilisé sous la forme :
Sep : asc(codeAscii) avec codeAscii = code ASCII du séparateur
La troisième ligne de chaque fichier contient la description des colonnes.
La quatrième ligne contient la description des types de données pour les colonnes en question.
Les autres lignes contiennent les données.
La première colonne contient le numéro d'erreur, il peut s'agit d'un numéro de message (GMES).
La deuxième colonne contient le statut de la donnée : U = mise à jour, I = insertion. On peut donc ainsi savoir précisément ce qu'il est advenu de chaque occurrence traitée.
La troisième colonne indique si la donnée n'est pas traitée (0), traitée avec des erreurs (1).
La quatrième colonne contient le numéro de l'occurrence. Il s'agit d'une numérotation générée automatiquement au moment de l'export des données.
Les autres colonnes décrivent les colonnes de la table.
Les colonnes NULLES ont pour valeur le caractère de code ASCII 0.
Les données qui n'ont pas pu être importées
Il y a dans le répertoire "identifiant de l'import", un sous répertoire "errors" dans lequel sont mis les fichiers contenant les données qui n'ont pas été importées sur la base de données cible car des erreurs ont été décelées.
Leur nom est : {IDi}_{table}.xls
Modèles d'export disponibles
L'objectif du Module Référentiels est de permettre le transfert, selon des critères variables, de données "cohérentes" d'un environnement vers un autre.
Cela implique que, les tables correspondant aux données à transférer soient regroupées dans des ensembles logiques appelés "modèles de l'export". Ils constituent donc en quelque sorte la matérialisation des connaissances fonctionnelles sur Cegid XRP Ultimate. Chaque "modèle" concerne une Application de Cegid XRP Ultimate (Achats, Finances, etc.).
Les modèles sont définis selon la catégorie des données : structure ou référentiel, paramétrage, exploitation.
Pour parvenir à définir les "modèles", il est nécessaire de disposer de la description des liens existant entre les tables. Le méta-modèle des données répond à ce besoin (GLTB, GTIJOI).
Les "modèles" dont le code commence par "QEF_CSE-BI" ou "QEF_CEE-BI" se rapporte à une Application.
Ceux commençant par "QEF_CRE" regroupent d'autres "modèles".
Ceux dont le code est de la forme XQEF_CLI correspondent à des "modèles" spécifiques au client précisé CLI.
Modèles d'export utilisables lors du lancement de la duplication d'établissements
QEF_CDE-BI Modèle général de sélection des données de structure, de paramétrage et d'exploitation de toutes les Applications se rapportant à un établissement quand la duplication s'effectue dans la même base de données
Il se compose de :
- QEF_CEE-BI Copie données d'exploitation d'un établissement, même base de données
- QEF_CSE-BI Copie données de structure et de paramétrage d'un établissement, même base de données
QEF_CEE-BI Modèle général de sélection des données d'exploitation de toutes les Applications se rapportant à un établissement quand la duplication s'effectue dans la même base de données
Il se compose de :
- QEF_CEE-BI-SAC Copie données d'exploitation d'un établissement, même base de données, Application Achats
QEF_CSE-BI Modèle général de sélection des données de structure et de paramétrage de toutes les Applications se rapportant à un établissement quand la duplication s'effectue dans la même base de données
Il se compose de :
- QEF_CSE-BI-ODE Copie données de structure et de paramétrage d'un établissement, même base de données, Application Structures générales
- QEF_CSE-BI-GTI Copie données de structure et de paramétrage d'un établissement, même base de données, Application Fondations
- QEF_CSE-BI-AMO Copie données de structure et de paramétrage d'un établissement, même base de données, Application Immobilisations
- QEF_CSE-BI-OBD Copie données de structure et de paramétrage d'un établissement, même base de données, Application Finances - Budgétaire
- QEF_CSE-BI-OCM Copie données de structure et de paramétrage d'un établissement, même base de données, Application Credit Management
- QEF_CSE-BI-OCT Copie données de structure et de paramétrage d'un établissement, même base de données, Application Finances
- QEF_CSE-BI-OCP Copie données de structure et de paramétrage d'un établissement, même base de données, Application Finances publiques
- QEF_CSE-BI-QLO Copie données de structure et de paramétrage d'un établissement, même base de données, Application Locations
- QEF_CSE-BI-SIR Copie données de structure et de paramétrage d'un établissement, même base de données, Application Supply Chain Foundations
- QEF_CSE-BI-SAC Copie données de structure et de paramétrage d'un établissement, même base de données, Application Achats
- QEF_CSE-BI-STK Copie données de structure et de paramétrage d'un établissement, même base de données, Application Stocks
- QEF_CSE-BI-SVT Copie données de structure et de paramétrage d'un établissement, même base de données, Application Ventes
- QEF_CSE-BI-QTA Copie données de structure et de paramétrage d'un établissement, même base de données, Application Temps et Activités
- QEF_CSE-BI-QPR Copie données de structure et de paramétrage d'un établissement, même base de données, Application Projets
- QEF_CSE-BI-QAM Copie données de structure et de paramétrage d'un établissement, même base de données, Application Maintenance
- QEF_CSE-BI-QRM Copie données de structure et de paramétrage d'un établissement, même base de données, Application XRM
- QEF_CSE-BI-QPN Copie données de structure et de paramétrage d'un établissement, même base de données, Application Planification
- QEF_CSE-BI-QDF Copie données de structure et de paramétrage d'un établissement, même base de données, Application Déplacements et Frais professionnels
- QEF_CSE-BI-QEA Copie données de structure et de paramétrage d'un établissement, même base de données, Application e-Achats
- QEF_CSE-BI-QAL Copie données de structure et de paramétrage d'un établissement, même base de données, Application Production
QEF_CSE-BI-ODE
Modèle général de sélection des données de structure et de paramétrage de l'Application Structures générales se rapportant à un établissement quand la duplication s'effectue dans la même base de données.
Il se compose de :
- QEE_CSE-BI-PARODE Paramètres Structures générales
- QEE_CSE-BI-ENTSTRODE Entités de structure Structures générales
- QEE_CSE-BI-ENTPARODE Entités de paramétrage Structures générales
QEF_CSE-BI-GTI
Modèle général de sélection des données de structure et de paramétrage de l'Application Fondations se rapportant à un établissement quand la duplication s'effectue dans la même base de données.
Il se compose de :
- QEE_CSE-BI-ENTPARGTI Entités de paramétrage Fondations
QEF_CSE-BI-AMO
Modèle général de sélection des données de structure et de paramétrage de l'Application Immobilisations se rapportant à un établissement quand la duplication s'effectue dans la même base de données.
Il se compose de :
- QEF_CSE-BI-ODE Copie données de structure et de paramétrage d'un établissement, même base de données, Application Structures générales. Nécessaires, elles sont liées aux données de l'Application Immobilisations.
- QEE_CSE-BI-PARAMO Paramètres Immobilisations
- QEE_CSE-BI-ENTSTRAMO Entités de structure Immobilisations
- QEE_CSE-BI-ENTPARAMO Entités de paramétrage Immobilisations
QEF_CSE-BI-OBD
Modèle général de sélection des données de structure et de paramétrage de l'Application Finances - Budgétaire se rapportant à un établissement quand la duplication s'effectue dans la même base de données.
Il se compose de :
- QEF_CSE-BI-ODE Copie données de structure et de paramétrage d'un établissement, même base de données, Application Structures générales
- QEE_CSE-BI-PAROBD Paramètres Finances - Budgétaire
- QEE_CSE-BI-ENTSTROBD Entités de structure Finances - Budgétaire
- QEE_CSE-BI-ENTPAROBD Entités de paramétrage Finances - Budgétaire
QEF_CSE-BI-OCM
Modèle général de sélection des données de structure et de paramétrage de l'Application Credit Management se rapportant à un établissement quand la duplication s'effectue dans la même base de données.
Il se compose de :
- QEF_CSE-BI-ODE Copie données de structure et de paramétrage d'un établissement, même base de données, Application Structures générales
- QEE_CSE-BI-PAROCM Paramètres Credit Management
- QEE_CSE-BI-ENTSTROCM Entités de structure Credit Management
- QEE_CSE-BI-ENTPAROCM Entités de paramétrage Credit Management
QEF_CSE-BI-OCT
Modèle général de sélection des données de structure et de paramétrage de l'Application Finances se rapportant à un établissement quand la duplication s'effectue dans la même base de données.
Il se compose de :
- QEF_CSE-BI-ODE Copie données de structure et de paramétrage d'un établissement, même base de données, Application Structures générales
- QEE_CSE-BI-PAROCT Paramètres Finances
- QEE_CSE-BI-ENTSTROCT Entités de structure Finances
- QEE_CSE-BI-ENTPAROCT Entités de paramétrage Finances
QEF_CSE-BI-OCP
Modèle général de sélection des données de structure et de paramétrage de l'Application Finances publiques se rapportant à un établissement quand la duplication s'effectue dans la même base de données.
Il se compose de :
- QEF_CSE-BI-ODE Copie données de structure et de paramétrage d'un établissement, même base de données, Application Structures générales
- QEE_CSE-BI-PAROCP Paramètres Finances publiques
- QEE_CSE-BI-ENTSTROCP Entités de structure Finances publiques
QEF_CSE-BI-QLO
Modèle général de sélection des données de structure et de paramétrage de l'Application Locations se rapportant à un établissement quand la duplication s'effectue dans la même base de données.
Il se compose de :
- QEF_CSE-BI-ODE Copie données de structure et de paramétrage d'un établissement, même base de données, Application Structures générales
- QEE_CSE-BI-PARQLO Paramètres Locations
- QEE_CSE-BI-ENTPARQLO Entités de paramétrage Locations
QEF_CSE-BI-SIR
Modèle général de sélection des données de structure et de paramétrage de l'Application Supply Chain Foundations se rapportant à un établissement quand la duplication s'effectue dans la même base de données.
Il se compose de :
- QEF_CSE-BI-ODE Copie données de structure et de paramétrage d'un établissement, même base de données, Application Structures générales
- QEE_CSE-BI-PARSIR Paramètres Supply Chain Foundations
- QEE_CSE-BI-ENTSTRSIR Entités de structure Supply Chain Foundations
- QEE_CSE-BI-ENTPARSIR Entités de paramétrage Supply Chain Foundations
QEF_CEE-BI-SAC
Modèle de sélection des données d'exploitation de l'Application Achats se rapportant à un établissement quand la duplication s'effectue dans la même base de données.
Il se compose de :
- QEF_CSE-BI-SAC Copie données de structure et de paramétrage d'un établissement, même base de données, Application Achats
- QEE_CEE-BI-ENTEXPSAC Entités d'exploitation Achats
QEF_CSE-BI-SAC
Modèle général de sélection des données de structure et de paramétrage de l'Application Achats se rapportant à un établissement quand la duplication s'effectue dans la même base de données.
Il se compose de :
- QEF_CSE-BI-SIR Copie données de structure et de paramétrage d'un établissement, même base de données, Application Supply Chain Foundations
- QEE_CSE-BI-PARSAC Paramètres Achats
- QEE_CSE-BI-ENTSTRSAC Entités de structure Achats
- QEE_CSE-BI-ENTPARSAC Entités de paramétrage Achats
QEF_CSE-BI-STK
Modèle général de sélection des données de structure et de paramétrage de l'Application Stocks se rapportant à un établissement quand la duplication s'effectue dans la même base de données.
Il se compose de :
- QEF_CSE-BI-SIR Copie données de structure et de paramétrage d'un établissement, même base de données, Application Supply Chain Foundations
- QEE_CSE-BI-PARSTK Paramètres Stocks
- QEE_CSE-BI-ENTSTRSTK Entités de structure Stocks
- QEE_CSE-BI-ENTPARSTK Entités de paramétrage Stocks
QEF_CSE-BI-SVT
Modèle général de sélection des données de structure et de paramétrage de l'Application Ventes se rapportant à un établissement quand la duplication s'effectue dans la même base de données.
Il se compose de :
- QEF_CSE-BI-SIR Copie données de structure et de paramétrage d'un établissement, même base de données, Application Supply Chain Foundations
- QEE_CSE-BI-PARSVT Paramètres Ventes
- QEE_CSE-BI-ENTSTRSVT Entités de structure Ventes
- QEE_CSE-BI-ENTPARSVT Entités de paramétrage Ventes
QEF_CSE-BI-QTA
Modèle général de sélection des données de structure et de paramétrage de l'Application Temps et Activités se rapportant à un établissement quand la duplication s'effectue dans la même base de données.
Il se compose de :
- QEF_CSE-BI-SIR Copie données de structure et de paramétrage d'un établissement, même base de données, Application Supply Chain Foundations
- QEE_CSE-BI-PARQTA Paramètres Temps et Activités
- QEE_CSE-BI-ENTSTRQTA Entités de structure Temps et Activités
- QEE_CSE-BI-ENTPARQTA Entités de paramétrage Temps et Activités
QEF_CSE-BI-QPR
Modèle général de sélection des données de structure et de paramétrage de l'Application Projets se rapportant à un établissement quand la duplication s'effectue dans la même base de données.
Il se compose de :
- QEF_CSE-BI-OBD Copie données de structure et de paramétrage d'un établissement, même base de données, Application Finances - Budgétaire
- QEF_CSE-BI-QAM Copie données de structure et de paramétrage d'un établissement, même base de données, Application Maintenance
- QEF_CSE-BI-SAC Copie données de structure et de paramétrage d'un établissement, même base de données, Application Achats
- QEF_CSE-BI-STK Copie données de structure et de paramétrage d'un établissement, même base de données, Application Stocks
- QEF_CSE-BI-SVT Copie données de structure et de paramétrage d'un établissement, même base de données, Application Ventes
- QEF_CSE-BI-QTA Copie données de structure et de paramétrage d'un établissement, même base de données, Application Temps et Activités
- QEF_CSE-BI-QPN Copie données de structure et de paramétrage d'un établissement, même base de données, Application Planification
- QEE_CSE-BI-PARQPR Paramètres Projets
- QEE_CSE-BI-ENTSTRQPR Entités de structure Projets
- QEE_CSE-BI-ENTPARQPR Entités de paramétrage Projets
QEF_CSE-BI-QAM
Modèle général de sélection des données de structure et de paramétrage de l'Application Maintenance se rapportant à un établissement quand la duplication s'effectue dans la même base de données.
Il se compose de :
- QEF_CSE-BI-SIR Copie données de structure et de paramétrage d'un établissement, même base de données, Application Supply Chain Foundations
- QEE_CSE-BI-PARQAM Paramètres Maintenance
- QEE_CSE-BI-ENTSTRQAM Entités de structure Maintenance
- QEE_CSE-BI-ENTPARQAM Entités de paramétrage Maintenance
Attention : ne pas exporter/importer ce modèle seul car il est incomplet, il dépend de Projets.
QEF_CSE-BI-QRM
Modèle général de sélection des données de structure et de paramétrage de l'Application XRM se rapportant à un établissement quand la duplication s'effectue dans la même base de données.
Il se compose de :
- QEF_CSE-BI-SVT Copie données de structure et de paramétrage d'un établissement, même base de données, Application Ventes
- QEE_CSE-BI-PARQRM Paramètres XRM
- QEE_CSE-BI-ENTSTRQRM Entités de structure XRM
- QEE_CSE-BI-STRQRM-LCE1 Table QRLCE
- QEE_CSE-BI-STRQRM-LCE2 Table QRLCE
- QEE_CSE-BI-ENTPARQRM Entités de paramétrage XRM
QEF_CSE-BI-QPN
Modèle général de sélection des données de structure et de paramétrage de l'Application Planification se rapportant à un établissement quand la duplication s'effectue dans la même base de données.
Il se compose de :
- QEF_CSE-BI-SAC Copie données de structure et de paramétrage d'un établissement, même base de données, Application Achats
- QEF_CSE-BI-SVT Copie données de structure et de paramétrage d'un établissement, même base de données, Application Ventes
- QEE_CSE-BI-PARQPN Paramètres Planification
- QEE_CSE-BI-ENTSTRQPN Entités de structure Planification
- QEE_CSE-BI-ENTPARQPN Entités de paramétrage Planification
QEF_CSE-BI-QDF
Modèle général de sélection des données de structure et de paramétrage de l'Application Déplacements et Frais professionnels se rapportant à un établissement quand la duplication s'effectue dans la même base de données.
Il se compose de :
- QEF_CSE-BI-ODE Copie données de structure et de paramétrage d'un établissement, même base de données, Application Structures générales
- QEE_CSE-BI-PARQDF Paramètres Déplacements et Frais professionnels
- QEE_CSE-BI-ENTSTRQDF Entités de structure Déplacements et Frais professionnels
- QEE_CSE-BI-ENTPARQDF Entités de paramétrage Déplacements et Frais professionnels
QEF_CSE-BI-QEA
Modèle général de sélection des données de structure et de paramétrage de l'Application e-Achats se rapportant à un établissement quand la duplication s'effectue dans la même base de données.
Il se compose de :
- QEF_CSE-BI-SIR Copie données de structure et de paramétrage d'un établissement, même base de données, Application Supply Chain Foundations
- QEE_CSE-BI-PARQEA Paramètres e-Achats
- QEE_CSE-BI-ENTPARQEA Entités de paramétrage e-Achats
QEF_CSE-BI-QAL
Modèle général de sélection des données de structure et de paramétrage de l'Application Production se rapportant à un établissement quand la duplication s'effectue dans la même base de données.
Il se compose de :
- QEF_CSE-BI-SIR Copie données de structure et de paramétrage d'un établissement, même base de données, Application Supply Chain Foundations
- QEE_CSE-BI-PARQAL Paramètres Production
- QEE_CSE-BI-ENTSTRQAL Entités de structure Production
- QEE_CSE-BI-ENTPARQAL Entités de paramétrage Production
Autres modèles d'export
QEF_CRE-BI-FIN Modèle général de sélection des données de structure et de paramétrage des Applications Structures générales, Finances, Finances - Budgétaire et Credit Management se rapportant à un établissement quand la duplication s'effectue dans la même base de données.
QEF_CRE-BI-FINAMO Modèle général de sélection des données de structure et de paramétrage des Applications Structures générales, Finances, Finances - Budgétaire, Credit Management et Immobilisations se rapportant à un établissement quand la duplication s'effectue dans la même base de données.
QEF_CRE-BI-SACSTK Modèle général de sélection des données de structure et de paramétrage des Applications Structures générales, Supply Chain Foundations, Achats et Stocks se rapportant à un établissement quand la duplication s'effectue dans la même base de données.
QEF_CRE-BI-SACSTKAMO Modèle général de sélection des données de structure et de paramétrage des Applications Structures générales, Supply Chain Foundations, Achats, Stocks et Immobilisations se rapportant à un établissement quand la duplication s'effectue dans la même base de données.
Paramétrage
Connexion à la base de données
Pour effectuer son travail de duplication, TCDETS a besoin de se connecter à la base de données avec un utilisateur disposant des droits suffisants pour :
- créer des tables temporaires (GLOBAL TEMPORARY TABLE), les alimenter, les lire et les supprimer ;
- de lire et écrire dans les tables (insertion, suppression, mise à jour).
Cet utilisateur et son mot de passe sont précisés dans la transaction GTPWD pour le type QEV.
Comportement en cas d'existence de données pour l'établissement cible (Paramètre QREPRM, occurrences EM et EM.nomTable)
Les occurrences EM et EM.nomTable du paramètre QREPRM conditionnent l'action faite par l'import lorsque des données existent déjà pour l'établissement cible.
Dans GPAR, la valeur du texte de ces occurrences peut être :
- I : si des données existent déjà pour l'établissement cible, on ne crée pas de nouvelles données lors d'un import à partir de l'établissement modèle.
- U : si des données existent déjà pour l'établissement cible, on ne met pas à jour ces données lors d'un import à partir de l'établissement modèle.
- UI ou IU : si des données existent déjà pour l'établissement cible, pas de création ni de mise à jour.
- S : si des données existent déjà pour l'établissement cible, elles sont supprimées avant création des données exportées.
- vide : pas d'action particulière ; création et mise à jour réalisées.
L'occurrence EM est générale et s'applique à toutes les tables.
L'occurrence EM.nomTable, où nomTable représente le nom de la table, permet de spécifier les actions pour une table particulière.
Inhibition systématique de la duplication d'une application (Paramètre QREPRM, occurrence QRE_$yyy)
Les occurrences commençant par QRE_$ du paramètre QREPRM permettent d'inhiber le traitement d'une application.
Dans GPAR, la valeur du texte de ces occurrences doit être positionnée à "skipped-application.APP=y" pour inhiber le traitement.
APP représente le code de l'application.
Exemple : texte "skipped-application.SAC=y" pour ne pas traiter les Achats.
Inhibition systématique de la duplication d'une table (Paramètre QREPRM, occurrence SK.nomTable)
Les occurrences SK.nomTable du paramètre QREPRM permettent d'inhiber le traitement d'une table. nomTable représente le code de la table.
Dans GPAR, la valeur du texte de ces occurrences doit être positionnée à :
- I : pour inhiber les créations sur la table ;
- U : pour inhiber les mises à jour sur la table ;
- U:nonColonne[,nomColonne] : pour inhiber la mise à jour sur certaines des colonnes de la table ;
- O : pour inhiber toute création et mise à jour sur la table.
Contraintes additionnelles : définition d'un contexte (Paramètre QRECXyyy)
Le contexte permet de demander la prise en compte de contraintes additionnelles.
Il s'agit de demander à ce qu'une table ne soit pas traitée par l'export, ou de demander au moment de l'import à ce qu'une table ne fasse pas l'objet d'insertions ou de mises à jour.
Le paramétrage standard précise non seulement les tables à traiter, mais également les contraintes à prendre en compte dans le cadre de la duplication :
- filtres pour la sélection des données ;
- verrous en insertion et mises à jour ;
- substitutions de valeurs à appliquer sur les colonnes.
Ces contraintes peuvent être complétées au besoin par paramétrage :
- par le biais des occurrences de la famille "EM" et "SK" ;
- par la définition de contextes.
Pour utiliser un contexte :
- Définir le contexte, c'est-à-dire créer un paramètre dans GPAD dont le nom débute obligatoirement par QRECX. Le nom du paramètre est le nom du contexte.
- Définir dans GPAR une occurrence par contrainte à gérer pour le contexte.
- Lors du lancement de la duplication d'établissements (TCDETS), saisir le nom du contexte dans le critère "Contexte" de la soumission.
Plusieurs types de modificateurs sont paramétrables : Filtres (applicables à l'export), Verrous (applicables à l'export et à l'import), Substitutions (applicables à l'import), Requêtes (applicables à l'export et à l'import), Actions (applicables à l'import) et Exclusivités (applicables à l'export et à l'import).
Paramétrage d'un verrou
Les effets de la contrainte de type verrou suivent la même logique et la même syntaxe que celle des inhibiteurs systématiques paramétrés par le biais des occurrences SK.nomTable du paramètre QREPRM.
Si les tables doivent être inhibées au cas par cas, selon les duplications, il conviendra de recourir aux "contextes" en définissant autant d'occurrences que de tables à inhiber.
| Colonne | Signification | Valeur |
|---|---|---|
| Paramètre (PADGTPAR) | Nom du contexte | Paramètre défini pour le contexte |
| Occurrence (OCCGTPAR) | Nom de la contrainte | Libre |
| Valeur testée 1 (TS1GTPAR) | Type de la contrainte | V = verrou |
| Valeur testée 2 (TS2GTPAR) | Sens de la contrainte | E = export ; I = import |
| Chaîne 1 (CH1GTPAR) | Table concernée | Code de la table en majuscule |
| Texte (TXTGTPAR) | Effet de la contrainte | Verrou à l'export, mettre "O" pour activer le verrou, et "N" pour l'inhiber. Verrou à l'import, saisir dans cette colonne la lettre "U" si les mises à jour doivent être inhibées, "I" si les insertions sont inhibées, "UI" si les insertions et les mises à jour sont inhibées. O = verrou actif N = verrou inactif U = verrou appliqué aux mises à jour seulement (import) U :colonne[,colonne] = inhibition de mise à jour sur les colonnes spécifiées seulement I = verrou appliqué aux insertions seulement (import) |
Paramétrage d'un filtre
Un filtre est une clause ajoutée aux requêtes de sélection des données à dupliquer. Elle précise des règles de sélection complémentaires. Les filtres peuvent être paramétrés à l'export seulement.
| Colonne | Signification | Valeur |
|---|---|---|
| Paramètre (PADGTPAR) | Nom du contexte | Paramètre défini pour le contexte |
| Occurrence (OCCGTPAR) | Nom de la contrainte | Libre |
| Valeur testée 1 (TS1GTPAR) | Type de la contrainte | F = filtre |
| Valeur testée 2 (TS2GTPAR) | Sens de la contrainte | E = export |
| Chaîne 1 (CH1GTPAR) | Table concernée | Code de la table en majuscule |
| Texte (TXTGTPAR) | Effet de la contrainte | Code SQL du filtre. Cette clause sera ajoutée aux clauses déjà présentes et liée à celles-ci par l'opérateur logique "and". Le code saisi ne doit donc pas commencer par un opérateur logique. |
| Signification | Valeur | |
|---|---|---|
| Nom du contexte | QRECX2 | |
| Nom de la contrainte | FILT.OEJRN | |
| Type de la contrainte | F | |
| Sens de la contrainte | E | |
| Table concernée | OEJRN | |
| Effet de la contrainte | numoejrn like 'A%' |
Le champ "Texte" de l'occurrence est limité à 60 caractères, si ce n'est pas suffisant, une extension du texte est possible en créant une occurrence de ce même paramètre avec :
| Colonne | Signification | Valeur |
|---|---|---|
| Paramètre (PADGTPAR) | Nom du contexte | Paramètre défini pour le contexte |
| Occurrence (OCCGTPAR) | Nom de la contrainte | Libre |
| Valeur testée 1 (TS1GTPAR) | Type de la contrainte | C = complément |
| Chaîne 1 (CH1GTPAR) | Occurrence à compléter | Code de l'occurrence à compléter |
| Valeur 1 (VA1GTPAR) | Numéro d'ordre | Numéro permettant d'ordonner les divers compléments |
| Texte (TXTGTPAR) | Suite de l'effet de la contrainte | Code SQL du filtre. Cette clause sera ajoutée à la clause. Elle doit commencer par un opérateur logique. |
| Signification | Valeur | |
|---|---|---|
| Nom du contexte | QRECX2 | |
| Nom de la contrainte | FLT2.OEJRN | |
| Type de la contrainte | C | |
| Occurrence à compléter | FILT.OEJRN | |
| Numéro d'ordre | 1 | |
| Effet de la contrainte | and etaoejrn <> 'U' |
Dans l'exemple, le texte " and etaoejrn <> 'U' " sera ajouté à la suite de " numoejrn like 'A%' ".
Si plusieurs compléments sont nécessaires, il suffira de créer autant d'occurrences de type C que nécessaire en les ordonnant via leur propriété "Valeur 1 (va1gtpar)".
Remarque : afin d'assurer la compréhension du code saisi entre SGBD, il est recommandé de recourir aux symboles ci-dessous plutôt que de mentionner les méthodes natives correspondantes.
| Fonction | Symbole |
|---|---|
| decode(argument, valeur, res1, res2) case argument when valeur then res1 else res2 | $DECODE (argument, valeur, res1, res2) |
| to_number(argment) convert(integer, argument) convert(float, argument) | $TONUMBER (argument) |
| instr(argument, motif) charindex(motif, argument) | $INSTR (argument, motif) |
| nvl(argument, valeur) isnull(argument, valeur) | $NVL (argument, valeur) |
| substr(argument, startPosition, length) | $SUBSTR(argument, startPosition, length) |
| ltrim(argument) | $LTRIM (argument) |
| rtrim(argument) | $RTRIM(argument) |
| from dual | $FROMDUAL |
Paramétrage d'une substitution
Une substitution est une règle demandant le remplacement systématique du contenu d'une colonne par une valeur donnée. Les substitutions peuvent être paramétrées à l'import seulement.
| Colonne | Signification | Valeur |
|---|---|---|
| Paramètre (PADGTPAR) | Nom du contexte | Paramètre défini pour le contexte |
| Occurrence (OCCGTPAR) | Nom de la contrainte | Libre |
| Valeur testée 1 (TS1GTPAR) | Type de la contrainte | S = substitution |
| Valeur testée 2 (TS2GTPAR) | Sens de la contrainte | I = import |
| Chaîne 1 (CH1GTPAR) | Table concernée | Code de la table en majuscule |
| Texte (TXTGTPAR) | Effet de la contrainte | Nom colonne = valeur[/Except=valeur[,valeur]] Exemple : dnpsgnpi = '000000' |
Ce type de contrainte admet des exceptions, c'est-à-dire des valeurs qui ne seront pas remplacées si elles sont rencontrées. Ces exceptions sont spécifiées par la notation /Except=... suivie de la liste des valeurs protégées.
Si plusieurs substitutions doivent être mises en place, il faudra créer autant d'occurrences de paramètre que de substitutions.
Paramétrage d'une requête
Une contrainte de type requête permet d'exécuter une requête complémentaire au cours du déroulement de la duplication. Le moment où celle-ci est invoquée dépend de l'opération en cours (export ou import), et il est spécifié par le nom de la contrainte elle-même. Plus précisément, c'est la façon dont commence ce nom qui est porteur de sens.
A l'export
Préfixe : ACT0 Appel à la fin de la création de la table temporaire destinée à collecter les données à dupliquer
Préfixe : ACT1 Appel à la fin de l'alimentation de la table temporaire destinée à collecter les données à dupliquer (juste avant la création des fichiers d'export)
A l'import
Préfixe : ACT0 Appel à la fin de la création de la table temporaire destinée à accueillir les données lues dans le fichier d'export pour la table à traiter
Préfixe : ACT1 Appel à la fin du chargement de la table temporaire
Préfixe : ACT2 Appel à la fin du marquage des occurrences dans la table temporaire (données à mettre à jour, données à insérer)
Le symbole $TMPTABLE! sera remplacé par le nom de la table temporaire. Il doit donc être utilisé si la requête porte sur cette table.
Le symbole $TIE! sera remplacé le tiers associé à l'établissement cible.
Le symbole $TIA! sera remplacé par l'adresse du tiers associé à l'établissement cible.
Le symbole $TID! sera remplacé par la domiciliation du tiers associé à l'établissement cible.
| Colonne | Signification | Valeur |
|---|---|---|
| Paramètre (PADGTPAR) | Nom du contexte | Paramètre défini pour le contexte |
| Occurrence (OCCGTPAR) | Nom de la contrainte | Libre |
| Valeur testée 1 (TS1GTPAR) | Type de la contrainte | R = requête |
| Valeur testée 2 (TS2GTPAR) | Sens de la contrainte | E = export ; I = import |
| Chaîne 1 (CH1GTPAR) | Table concernée | Code de la table en majuscule |
| Texte (TXTGTPAR) | Effet de la contrainte | Code SQL de la requête à exécuter |
| Signification | Valeur | |
|---|---|---|
| Nom du contexte | QRECX2 | |
| Nom de la contrainte | ACT1OCBNQ | |
| Type de la contrainte | R | |
| Sens de la contrainte | I | |
| Table concernée | OCBNQ | |
| Effet de la contrainte | update $TMPTABLE! set tieocbnq=etsocbnq |
Si besoin, des occurrences de type C (Complément) peuvent être créées (voir paramétrage d'un filtre).
Paramétrage d'une exclusivité
Les clauses d'exclusivité permettent de faire en sorte que seules certaines tables soient traitées par la duplication. Cela peut s'avérer utile dans un contexte de mise à jour récurrent par exemple.
Le recours à ce type de contrainte suppose toutefois de maîtriser la duplication car on court le risque d'avoir des rejets inhérents à l'absence de tables oubliées dans la liste des exclusivités et pourtant nécessaires pour garder la cohérence des données.
Concrètement, il faut une occurrence de paramètre par table devant figurer dans la liste des tables à traiter. Toute table ne faisant pas l'objet d'un tel paramétrage sera de facto non traitée si le contexte concerné est utilisé. Pour des raisons de performance, il est préférable d'utiliser ce type de contrainte à l'export.
| Colonne | Signification | Valeur |
|---|---|---|
| Paramètre (PADGTPAR) | Nom du contexte | Paramètre défini pour le contexte |
| Occurrence (OCCGTPAR) | Nom de la contrainte | Libre |
| Valeur testée 1 (TS1GTPAR) | Type de la contrainte | E = exclusivité |
| Valeur testée 2 (TS2GTPAR) | Sens de la contrainte | E = export ; I = import |
| Chaîne 1 (CH1GTPAR) | Table concernée | Code de la table en majuscule |
| Texte (TXTGTPAR) | Effet de la contrainte | Non utilisé |
| Signification | Valeur | |
|---|---|---|
| Nom du contexte | QRECX2 | |
| Nom de la contrainte | EXCL.SARAF | |
| Type de la contrainte | E | |
| Sens de la contrainte | E | |
| Table concernée | SARAF |
Application des autorisations/interdictions de la transaction GTMME (Paramètre QREPRM, occurrence USEGTMME)
L'occurrence USEGTMME du paramètre QREPRM est éventuellement utilisée pour placer le traitement TCDETS dans un contexte où lors de l'import des données, les autorisations/interdictions paramétrées dans la transaction GTMME sont prises en compte (saisir "N" dans le champ "Texte" de cette occurrence).
Par exemple, le message GTMME007 - La création de données n'est pas autorisée sur l'établissement $1 pour l'entité $2 apparaît si la création est interdite pour une table dans la transaction GTMME, ceci quelle que soit la valeur du critère "GTMME" de la soumission de TCDETS.
Techniquement, les procédures stockées que TCDETS invoque s'exécutent comme si elles étaient appelées en interactif, c'est-à-dire dans les transactions de saisie de l'interface utilisateur.
Par défaut, cette occurrence n'existe pas ou a la valeur "O" dans le champ "Texte".
Les procédures stockées sont invoquées dans le contexte de la duplication.
Le paramétrage de la transaction GTMME est ignoré, sauf si le critère "GTMME" de la soumission de TCDETS précise une exception.
Réduire le volume de fichiers de compte-rendu générés
En positionnant le champ "Texte" de l'occurrence SAVEBI du paramètre QREPRM à la valeur N, les fichiers de compte-rendu de l'import des données dans l'établissement cible ne sont pas générés sur le serveur de traitements. Cela réduit le volume de fichiers lorsque le traitement de duplication d'établissements est fréquemment utilisé.
Import des données en ignorant leur état
L'occurrence ETAMODE du paramètre QREPRM est éventuellement utilisée pour placer le traitement TCDETS dans un contexte où lors de l'import des données, l'état des données est ignoré. Ceci permet de ne pas bloquer l'import, si des données importées à l'état "Inactif" ou "Supprimé", sont référencées dans d'autres données importées. Généralement, la création d'une donnée sur l'établissement cible est bloquée si elle fait référence à une autre donnée qui n'est pas à l'état "Actif".
Si le champ "Texte" de l'occurrence est positionné à la valeur "F" :
- lors de la création de la donnée sur l'établissement cible, son état est forcé à "Actif" ;
- en fin d'import, la donnée est mise à son état initial.
Exploitation des traces et rejets
Divers fichiers de traces sont générés par le traitement de duplication (TCDETS). Parmi eux, il y a les fichiers de rejets, qui indiquent sous forme de message, la cause de la "non duplication" de telle ou telle donnée.
Quand ces cas se présentent, il faut ouvrir les fichiers de rejets et analyser le code du message. Cela renvoie en général à des rejets intervenus dans d'autres tables et provoquant des anomalies en cascade. Souvent, la correction d'une anomalie dans une table permet de corriger de nombreux rejets corrélés.
1) Aviser dans le compte-rendu du traitement, une table pour laquelle des rejets sont signalés.
2) Récupérer le fichier de rejets soit directement dans le sous-répertoire "errors", soit via le traitement TQEVD.
3) Ouvrir le fichier de rejets, noter le code du message dans la première colonne
4) Via GMES, rechercher le message d'erreur complet via son code et en déduire la cause de l'anomalie.
Purge des répertoires
Obsolète. Utilisé lorsque les fichiers de trace des exports et imports étaient générés dans le répertoire IAC_HOME/qenvironnements.
Les traces générées par le traitement TCDETS sont assez nombreuses et volumineuses et il convient d'en faire une purge régulière sous peine de saturer l'espace disque disponible. En standard, on purge automatiquement toutes les traces datant de plus de 20 jours à la date de son exécution.
Ce délai est réglable par le paramètre QREPRM, occurrence TRC.RM.
- Valeur 1 = nombre de jours ;
- Texte = O si cette occurrence est active.