Cegid XRP Ultimate | I3 Actualisé le 06/10/2022 |
|||
| Réplication | |||
| Module Archivage | |||
| Traitements d'archivage |
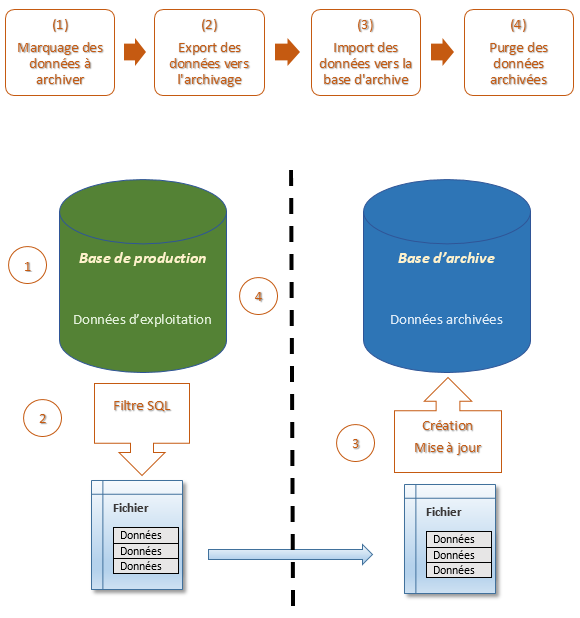
| 1 - Marquage des données à archiver Chaque application contient des entités susceptibles d'être archivées. Par exemple, pour Finances, les entités susceptibles d'être archivées sont : - Ecritures et mouvements ; - Pièces et associations ; - ... Afin de pouvoir archiver ces entités, une table d'archivage a été créée pour chaque entité de chaque application. Cette table est une représentation minimaliste composée des colonnes minimums et nécessaires pour retrouver l'information principale de la table "maître" : - la table OCAEC est la table d'archivage de la table principale OCECR ; - la table SAACD est la table d'archivage de la table principale SACDA ; - la table SVACD est la table d'archivage de la table principale SVCDV ; - ... La mise à jour de ces tables est effectuée via un traitement. Ce traitement renseignera automatiquement les colonnes adéquates des tables d'archivage. Une fois ce marquage réalisé, il est donc possible, à partir de ces tables, de retrouver toutes les informations liées à une entité. On dit alors que les données contenues dans ces tables d'archivage sont des données "flaggées". 2 - Export des données vers l'archivage Cette étape s'appuie sur la lecture de l'arbre défini dans la transaction de la gestion hiérarchique des tables à archiver (GKHTAG). La lecture de l'arbre conduit à la génération de fichiers contenant les données de chaque table de l'arbre. 3 - Import des données dans la base d'archive Cette étape consiste à "réinjecter" les fichiers de données dans la base d'archive. Remarque : la priorité, lors du rechargement, est donnée à l'UPDATE. Si ce dernier ne fonctionne pas, le traitement d'INSERT sera réalisé. 4 - Purge des données archivées Cette étape consiste à supprimer physiquement les données de la base de production qui ont été archivées. |
| Principe de connexion |
| Avant de lancer les traitements d'export, import et épuration, certaines tables doivent être renseignées (Cf. Paramétrages). Le principe de connexion aux bases de données est réalisé de la manière suivante, c'est le même pour les traitements TTEXP, TTIMP, TTEPU : - Première connexion sur la base définie dans le fichier de propriétés. L'utilisateur de connexion est celui ramené par le lancement du traitement (gtulan). Cette première connexion permet de récupérer les informations correspondant aux caractéristiques du ou des transfert(s). Une fois récupérées, on se déconnecte. - Deuxième connexion sur la base définie dans la transaction détail des environnements (GMIDSI), forme détail Base. La concaténation des champs Serveur et Base correspond au chemin d'accès à la base de production. L'utilisateur de connexion est celui défini, dans cette même forme détail, dans le champ Utilisateur d'exécution. Dans ce cas, le mot de passe est celui défini dans le champ Mot de passe. Cette deuxième connexion permet d'exécuter réellement le traitement. |
| Traitement d'archivage pour l'export des données (TTEXP) |
| Le traitement TTEXP permet de décharger des données à partir de la base de données. |
| Initialisation |
| Le lancement du traitement d'export est réalisé par le biais du mnémonique TTEXP. L'écran de TTEXP permet de définir jusqu'à 5 transferts. Ces transferts doivent, au préalable, avoir été définis dans : - la transaction des noms des transferts (GMINTR) ; - la transaction de la gestion hiérarchique des tables à archiver (GKHTAG). La hiérarchie définie dans GKHTAG représente les tables dont les données seront déchargées. Par défaut, toutes les données de ces tables, correspondant aux données flaggées (table d'archivage), seront exportées. Rappelons qu'il est possible de définir un filtre permettant de restreindre l'ensemble des données exportées. Ce filtre est à définir au niveau de la transaction des clauses d'exportation (GMICEX). Pour un transfert donné, il existe deux environnements : - un environnement de production (base de production) ; - un environnement d'archive (base d'archive). Cette association est définie dans la transaction des transferts entre environnements (GMISIT). Les environnements doivent, au préalable, avoir été définis dans la transaction détail des environnements (GMIDSI). |
| Export des données |
| Le déchargement des données de la base de production est effectué dans des fichiers. Il existe pour une table donnée de la hiérarchie (GKHTAG), deux types de fichiers : --> fichier de description de la table. Il contient la liste des colonnes, ainsi que leurs attributs (nom, type, taille, ...). Ce fichier est généré dans le répertoire de type DCTRL de l'environnement de production défini dans la transaction des répertoires par transfert (GMIREP). Le nom du fichier est : [ENVPRODUCTION]_[ENVARCHIVE]_[TRANSFERT]_[TABLE].dsc Il contient les informations suivantes : - table.name : correspond au nom de la table traitée ; - colum.count : correspond au nombre de colonnes dans la table ; - import.statement : correspond au type d'action réalisée ; - column.[i] : correspond aux caractéristiques de la ième colonne (nom; type; taille; index unique (U si la colonne fait partie de l'index unique); colonne nulle (N si la colonne ne peut pas être nulle); précision; nombre de chiffres après la virgule) ; - checksum.data : correspond à la valeur du checksum du fichier de données correspond à la table ; - checksum.desc : correspond à la valeur du checksum du fichier. --> fichier de données de la table. Il contient l'ensemble des données. Ce fichier est généré dans le répertoire de type DDATA de l'environnement de production défini dans la transaction des répertoires par transfert (GMIREP). Le nom du fichier est : [ENVPRODUCTION]_[ENVARCHIVE]_[TRANSFERT]_[TABLE].dat Il contient les données séparées par le caractère séparateur défini au niveau de la transaction des transferts entre environnements (GMISIT). L'étape d'export génère deux fichiers supplémentaires : --> fichier de description du ou des transferts exportés. Le nom du fichier est : [ENVPRODUCTION]_[ENVARCHIVE]_export.dsc Il contient la liste des transferts pris en compte pour le traitement d'export. --> fichier de contrôle par transfert. Il contient, entre autres, les tables qui ont été exportées et le nombre d'enregistrements exportés pour ces tables. Le nom du fichier est : [ENVPRODUCTION]_[ENVARCHIVE]_[TRANSFERT].ctl Il contient les informations suivantes : - table.count : correspond au nombre de tables traitées ; - table.[i] : correspond aux caractéristiques de la ième table (nom de la table; version de la table; nombre d'enregistrements exportés; checksum du fichier de description de la table; checksum du fichier de données de la table) ; - archive.number : correspond au numéro d'archive ; - product.release.date : correspond à la date de la release de la base de production ; - archive.release.date : correspond à la date de la release de la base d'archive ; - checksum : correspond à la valeur du checksum du fichier. Ces deux fichiers (fichier de description et fichier de contrôle) sont générés dans le répertoire DCTRL de l'environnement de production. Remarque : Les fichiers sont compressés afin d'améliorer leur transfert sur la machine d'archive. |
| Conditions de lancement de l'étape d'export |
| Nous verrons par la suite qu'un fichier de type compte rendu est généré au terme de l'import des données. Ce fichier, une fois généré (traitement d'import), est transféré dans le répertoire de type RCTRL de l'environnement de production défini dans la transaction des répertoires par transfert (GMIREP). Ce fichier contient, en particulier, la caractéristique archive.state. Cette caractéristique indique l'état de l'import des données. Les règles pour pouvoir lancer un export pour un transfert A sont les suivantes : - Si le fichier de compte rendu du transfert A n'existe pas, alors l'export du transfert A peut être lancé ; - Si le fichier existe : - archive.state = 1, alors l'import du transfert A s'est bien déroulé. On peut relancer l'export des données du transfert A. - archive.state = -1, alors il y a eu un problème au niveau de l'import du transfert A. L'export du transfert A ne peut pas être relancé. |
| Traitement d'archivage pour l'import des données (TTIMP) |
| Le traitement TTIMP permet d'archiver des données dans une base, à partir de la lecture de fichiers. |
| Initialisation |
| Le lancement du traitement d'import est réalisé par le biais du mnémonique TTIMP. L'écran de TTIMP permet de définir jusqu'à 5 transferts. Ces transferts doivent, au préalable, avoir été définis dans la transaction des noms des transferts (GMINTR). Nous avons vu précédemment, que l'étape d'export génère des fichiers. Ces fichiers, au terme de l'export, sont transférés dans les répertoires ci-dessous : - les fichiers de description des tables, description du traitement et de contrôle du ou des transfert(s) sont localisés dans le répertoire de type RCTRL de l'environnement d'archive ; - les fichiers de données sont localisés dans le répertoire de type RDATA de l'environnement d'archive. La lecture du fichier de contrôle pour un transfert donné, permet de connaître la liste des tables à prendre en compte. |
| Transfert du fichier |
| Au terme de la compression, le traitement d'import réalise le transfert (FTP) du fichier de compte rendu dans le répertoire RCTRL de l'environnement de production. |
| Validation |
| Le traitement d'import valide les modifications sur la base de données (COMMIT) toutes les 10000 lignes de données importées. Ce chiffre n'est pas paramétrable. |
| Historisation |
| Si l'import se termine correctement, le traitement historise l'action. Cette historisation est réalisée dans la table cmihtr de la machine d'archive avec les informations suivantes. - Nom : correspond au nom du transfert importé. - Site source : correspond à l'environnement sur lequel le traitement d'import a été exécuté. - Dernier transfert réussi : correspond au numéro d'archive. - Données intégrées : correspond au nombre de données importées. - Date de release : correspond à la date de release de la machine d'archive. - Création : correspond à l'utilisateur d'exécution du traitement. |
| Traitement d'archivage pour l'épuration des données (TTEPU) |
| Le traitement TTEPU permet d'épurer des données dans une base. |
| Initialisation |
| Le lancement du traitement d'épuration est réalisé par le biais du mnémonique TTEPU. L'écran de TTEPU permet de définir jusqu'à 5 transferts. Ces transferts doivent, au préalable, avoir été définis dans la transaction des noms des transferts (GMINTR). Attention L'épuration des données n'est réalisable que pour un transfert de type archivage + épuration. S'il s'agit d'un transfert archivage sans épuration le traitement TTEPU ne pourra pas être exécuté. |
| Epuration des données |
| La lecture de l'arborescence du transfert définie dans la transaction de la gestion hiérarchique des tables à archiver (GKHTAG) permet de connaître le nom de la table d'archive (Il s'agit, en fait, de la première table dans l'arborescence), et celui de la table associée (chaque entité susceptible d'être archivée est associée à une table d'archive). Le traitement d'épuration supprime toutes les données de la table d'archive pour lesquelles le numéro d'archive est renseigné (Le marquage des lignes de données dans la table d'archive est effectué lors de l'export des données). Il supprime aussi les données des tables associées, à partir des traitements d'épuration déjà existants. Cela signifie que le traitement d'épuration respecte les règles d'intégrité des traitements d'épuration déjà existants. Exemple : Soit l'exemple de l'épuration des écritures, mouvements. Le lien existant entre les écritures et les mouvements est le suivant : - OCECR - OCMVC Soit A, le traitement d'épuration des écritures et mouvements actuellement disponible (TCEX). Ce traitement supprime les écritures et mouvements en respectant plusieurs contraintes (règles d'intégrité). Soit, l'exemple d'épuration des écritures, mouvements. Le lien existant entre les écritures et les mouvements, dans ce cas de figure, est le suivant : - OCAEC - OCECR - OCMVC Soit B, le traitement d'épuration des écritures et mouvements. Ce traitement, supprime les données de la table OCAEC (table d'archivage) ET lance le traitement associé à l'épuration des écritures et mouvements (TCEX - traitement A). |
| Validation |
| Le traitement d'épuration valide les modifications sur la base de données (COMMIT) toutes les 10000 lignes de données épurées. Ce chiffre n'est pas paramétrable. |
| Historisation |
| Si l'épuration se termine correctement, le traitement historise l'action. Cette historisation est réalisée dans la table cmihtr de la machine de production avec les informations suivantes. - Nom : correspond au nom du transfert épuré. - Site source : correspond à l'environnement sur lequel le traitement d'épuration a été exécuté. - Dernier transfert réussi : correspond au numéro d'archive. - Données intégrées : correspond au nombre de données épurées. - Date de release : correspond à la date de release de la machine de production. - Création : correspond à l'utilisateur d'exécution du traitement. |
| Traitement d'archivage sans épuration |
| Les tables devant être exportées, importées et/ou épurées pour un transfert donné, sont décrites, sous forme d'arborescence, dans la gestion hiérarchique des tables à archiver (GKHTAG). La première table de cette arborescence indique si le transfert peut être épuré ou non. En effet, toutes les entités, susceptibles d'être épurées, sont référencées dans la transaction Référence des entités à archiver (GACH). Pour un transfert donné, si le nom de la première table de l'arborescence est présent dans GACH, alors le transfert peut être épuré. Si le nom n'est pas dans GACH, alors il s'agit d'un transfert sans épuration. Suivant la première table de l'arborescence, on pourra ainsi choisir entre deux types d'archivage : - archivage avec épuration ; - archivage sans épuration. |
| Entités archivables/épurables |
| Finances - Epuration des écritures, mouvements ; - Pièces et associations ; - Cumuls par compte ; - Cumuls par tiers ; - Cumuls par CGR ; - Cumuls paramétrables ; - Cumuls par type de pièces ; - Aide à la déclaration de TVA. Credit Management - Actions et recouvrement. Achats - Commandes, réceptions et factures. Stocks - Inventaires ; - Inventaires de clôture et historique du stock ; - Mouvements de stock ; - Lots. Supply Chain Foundations - Prix à date ; - PUMP. Production - Formules ; - Besoins ; - Ordres ; - Plans. Ventes - Commandes, livraisons et factures ; - Statistiques ; - Remises de Fin de Période (PSTR) ; - Commandes EDI (PICD) ; - Trace des lots vendus (PTLV) ; - Abonnements (PABO). |
| Paramétrages |
| Afin de pouvoir exécuter les traitements, certaines transactions doivent être renseignées. |
| Fondations |
| GOBJ - Objets |
| Le nom de l'objet correspondant au module Archivage est : com.qualiac.mir.Archivage |
| GTRA - Transactions |
| Les transactions associées au module sont au nombre de 3 (ces transactions ont pour objet gttdyn): MITEXP : Cette transaction correspond au Traitement d'archivage pour l'export des données provenant de la base de Production. MITIMP : Cette transaction correspond au Traitement d'archivage pour l'import des données dans la base d'Archive. MITEPU : Cette transaction correspond au Traitement d'archivage pour l'épuration des données de la base de Production. D'autres transactions ont été développées permettant le paramétrage. GTIACH : Cette transaction permet de référencer les entités à archiver. MIIHTA : Cette transaction permet de définir la hiérarchie des tables devant être archivées. Les autres transactions nécessaires au paramétrage sont, pour certaines, aussi utilisées pour paramétrer l'application Réplication. De ce fait, ces transactions doivent déjà exister. En voici tout de même la liste : - GMIDSI, GMIREP, GMINTR, GMISIT, GMICEX, GLTB et GTIJOI L'utilisation de ces transactions est décrite plus loin dans le document. |
| GTRB - Traitements |
| Définir dans cette transaction, les 3 traitements associés au module Archivage : - MITEXP - MITIMP - MITEPU |
| GCTR - Critères des traitements |
| Les transactions MITEXP, MITIMP et MITEPU ont pour objet gttdyn. Ce qui implique que la définition des critères des traitements dans GCTR correspond en fait à l'ergonomie du masque de chaque transaction. Ces critères sont au nombre de 5 par traitement : - CHAINE1D : Correspond au champ Transfert n°1 permettant de saisir le nom du premier transfert. - CHAINE2D : Correspond au champ Transfert n°2 permettant de saisir le nom du deuxième transfert. - CHAINE3D : Correspond au champ Transfert n°3 permettant de saisir le nom du troisième transfert. - CHAINE4D : Correspond au champ Transfert n°4 permettant de saisir le nom du quatrième transfert. - CHAINE5D : Correspond au champ Transfert n°5 permettant de saisir le nom du cinquième transfert. La définition de ces 5 critères de traitements signifie que vous ne pourrez lancer que 5 transferts par traitement à la fois. |
| GMNU - Mnémoniques |
| Définir dans cette transaction, les 3 transactions suivantes : - TTEXP - TTIMP - TTEPU |
| GPTH - Chemins d'accès |
| Un chemin est défini pour l'utilisateur PUBLIC, l'application MIR, le type JAV et le serveur NOM_SERVEUR: - Localisation du fichier qualiacmir.jar exemple de chemin : /oracs/exp/mir/bin/lib/qualiacmir.jar |
| GOUT - Outils |
| Définir dans cette transaction l'outil permettant de lancer les programmes Java. ATTENTION Il est nécessaire d'ajouter les options Xms et Xmx au lancement de l'outil JAVA. La ligne de commande devient alors : /opt/java[version]/bin/java -Xms128m -Xmx256m L'option Xms correspond à la mémoire réservée au démarrage du programme Java. L'option Xmx correspond à la mémoire maximum autorisée pendant le fonctionnement. Ces valeurs dépendent fortement de la quantité de mémoire disponible sur la machine. |
| GACH - Référence des entités à archiver |
| Cette gestion permet de définir les différentes entités pouvant être archivées. L'archivage (export - import - épuration) d'une entité n'est possible que si elle est définie dans cette gestion. |
| Serveurs de données |
| Localisation des fichiers |
| Comme nous l'avons vu ci-dessus, deux fichiers sont nécessaires : - qualiacdb.properties : fichier des propriétés ; - qualiacmir.jar : fichier permettant l'exécution. Ces deux fichiers doivent se trouver dans les répertoires définis dans la transaction des Chemins d'accès (GPTH). |
| Les transactions de paramétrage du module |
| GMIDSI - Détail des environnements |
| Cette gestion permet de définir les caractéristiques des environnements (base de données) sur lesquels les traitements seront exécutés. |
| GMIREP - Répertoire par transfert |
| Cette gestion permet de définir les répertoires des environnements (base de données) dans lesquels seront stockés les fichiers générés par les traitements. |
| GMINTR - Noms des transferts |
| Cette gestion permet de définir le nom du transfert à partir duquel les traitements seront exécutés. |
| GMISIT - Transferts entre environnements |
| Cette gestion permet de définir pour un transfert donné, les environnements (base de données) de production (export des données) et d'archivage (import des données). |
| GKHTAG - Gestion hiérarchique des tables à archiver |
| Avant de lancer le traitement d'archivage des données, il faut définir un transfert associé à une hiérarchie de tables à archiver. |
| GMICEX - Clause d'exportation |
| Cette gestion permet de définir une clause d'exportation pour la table sélectionnée dans la hiérarchie des tables à archiver. |
| GLTB - Liens entre les tables |
| Cette gestion permet de définir les liens existants entre les tables. |
| GTIJOI - Jointures |
| Cette gestion permet de décrire les jointures entre les tables liées. |
| GMIELR - En-tête des regroupements logiques |
| Cette gestion permet de regrouper les transferts afin de pouvoir Exporter, Importer ou Epurer des ensembles de transferts. |